Optimización de Hiperparámetros OCR con Ray Tune para Documentos Académicos en Español
Estado del Arte: Motores OCR
EasyOCR
JaidedAI
CRAFT + CRNN
- 80+ idiomas
- Fácil de usar
- Baja configurabilidad
PaddleOCR
Baidu / PaddlePaddle
DB + SVTR (PP-OCRv5)
- Alta configurabilidad
- Pipeline modular
- Soporte español dedicado
DocTR
Mindee
DB/LinkNet + CRNN/SAR
- TF y PyTorch
- Soporte español limitado
- Rápido en inferencia

Pipeline de un sistema OCR moderno
Metodología: 5 Fases

Fases de la metodología experimental
1
Preparación del datasetPDF → 300 DPI + GT
2
Benchmark comparativo3 motores, CER/WER
3
Espacio de búsqueda7 hiperparámetros
4
Optimización64 trials, TPE
5
Validación45 páginas completas
Arquitectura: Microservicios Docker
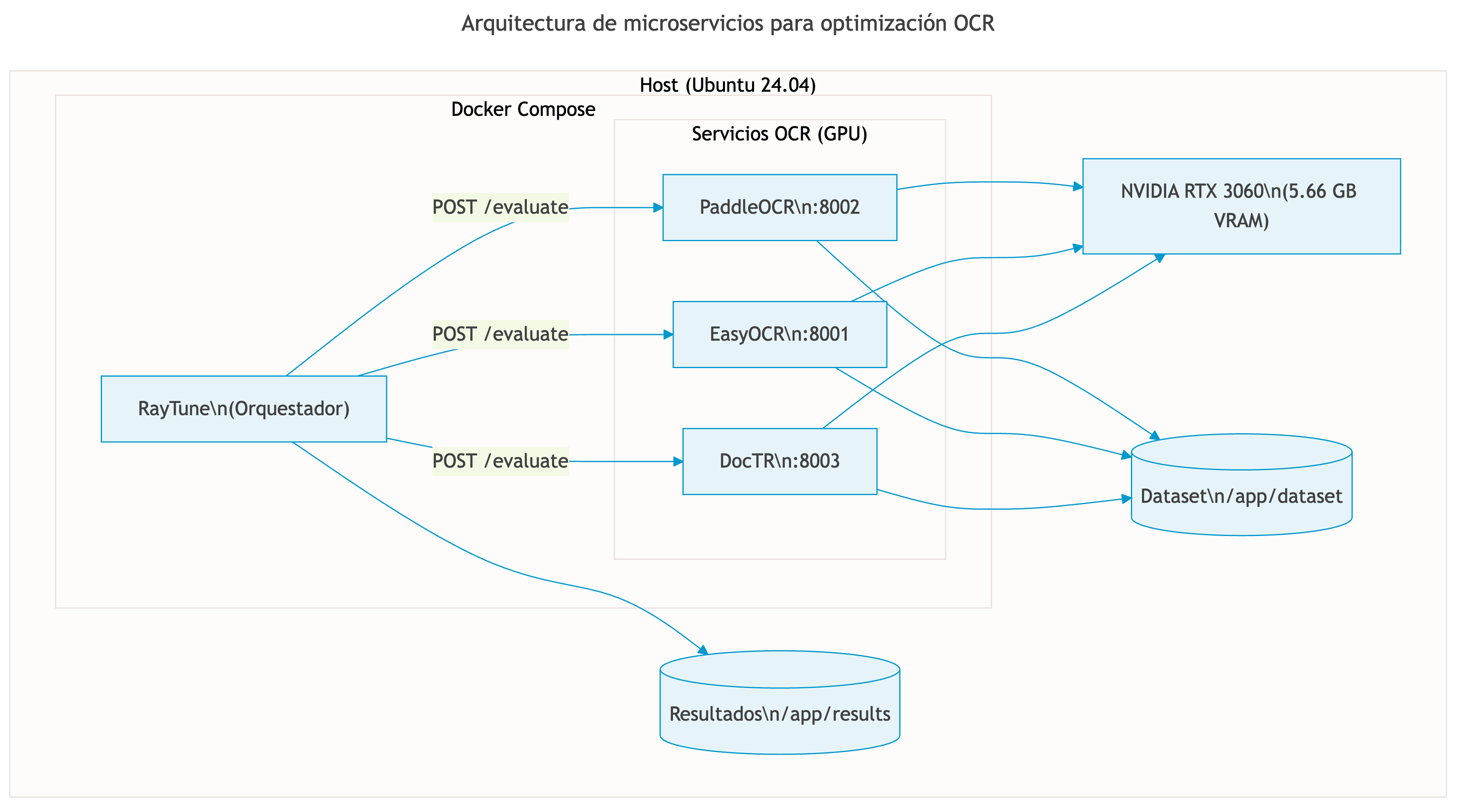
Arquitectura de microservicios para optimización OCR
- Contenedor Ray Tune: Orquestador de trials (Optuna TPE)
- Contenedor OCR: PaddleOCR con acceso GPU
- Comunicación: REST API (HTTP POST /evaluate)
- Respuesta: JSON {CER, WER, TIME}
- Docker Compose: Despliegue reproducible
Hardware:
RTX 3060 Laptop (5.66 GB VRAM)
AMD Ryzen 7 5800H
16 GB DDR4 | Ubuntu 24.04
RTX 3060 Laptop (5.66 GB VRAM)
AMD Ryzen 7 5800H
16 GB DDR4 | Ubuntu 24.04
Espacio de Búsqueda: 7 Hiperparámetros
| Parámetro | Tipo | Rango |
|---|---|---|
textline_orientation | Booleano | True / False |
use_doc_orientation_classify | Booleano | True / False |
use_doc_unwarping | Booleano | True / False |
text_det_thresh | Continuo | [0.01, 0.50] |
text_det_box_thresh | Continuo | [0.01, 0.90] |
text_rec_score_thresh | Continuo | [0.01, 0.99] |
text_det_unclip_ratio | Fijo | 0.0 |

Ciclo de optimización con Ray Tune y Optuna
Algoritmo: TPE (Tree-structured Parzen Estimator)
Trials: 64 | Concurrencia: 2 workers
Métrica: Minimizar CER
Trials: 64 | Concurrencia: 2 workers
Métrica: Minimizar CER